

Wer an
Dabei basiert der größte Fortschritt, den die Forschung in den letzten Jahren gemacht hat, auf den stetig wachsenden Modellen. Die durchschnittliche Anzahl an lernbaren Parametern – die Eigenschaften der künstlichen Neuronen – wächst seit der „
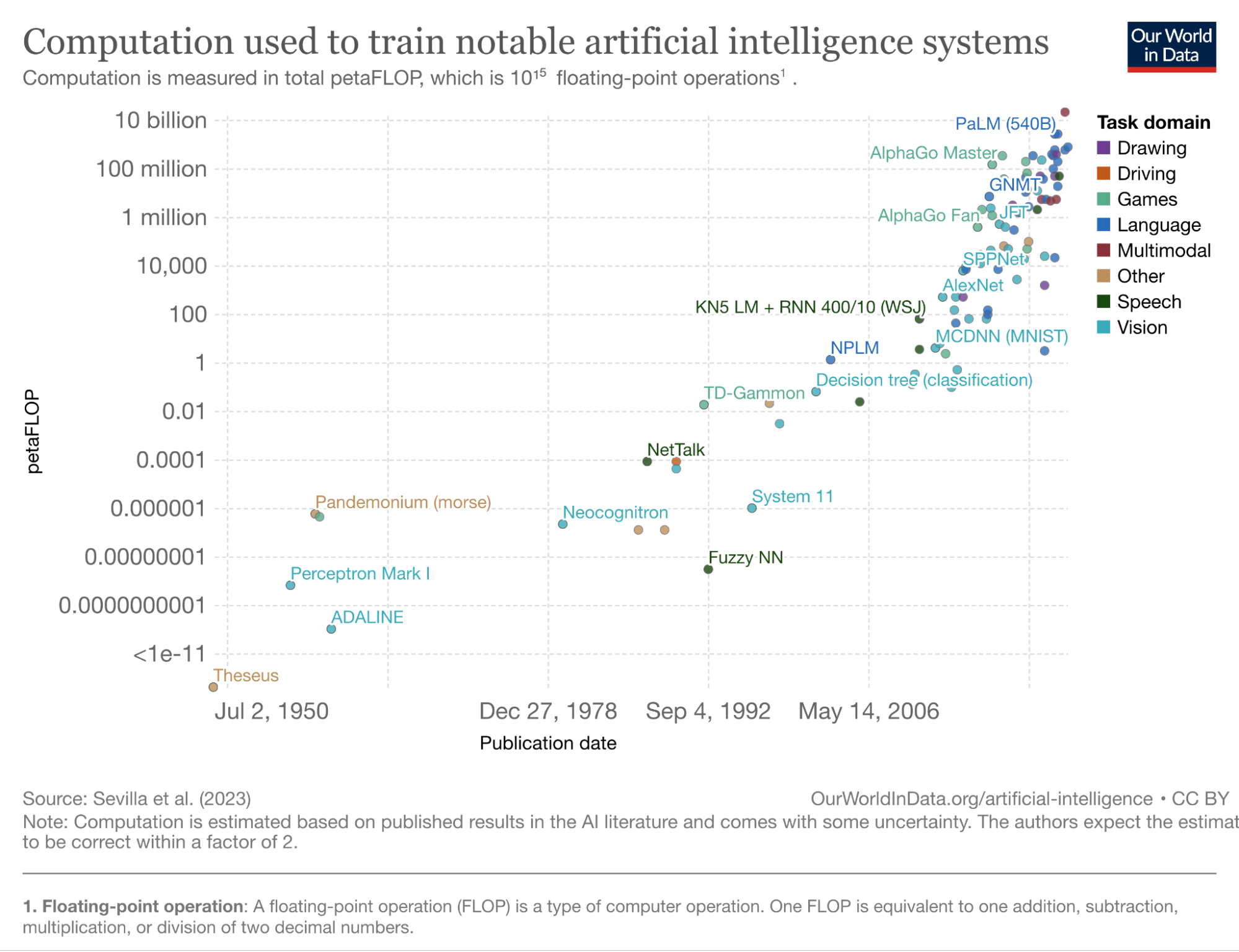
So werden die Modelle immer komplexer und energieaufwändiger, während die Optimierung des Energieverbrauchs oft vernachlässigt wird. Doch mit besseren Modellen wird auch das Potential für substanzielle Verbesserungen immer kleiner und in vielen Bereichen gibt es seit Jahren ein Kopf-an-Kopf-Rennen um das Erreichen der letzten paar Prozent. Da stellt sich die Frage: Wie viel Genauigkeit wird wirklich gebraucht und wie viel Energie sollte dafür investiert werden? Verfolgt die Forschung die richtigen Ziele?
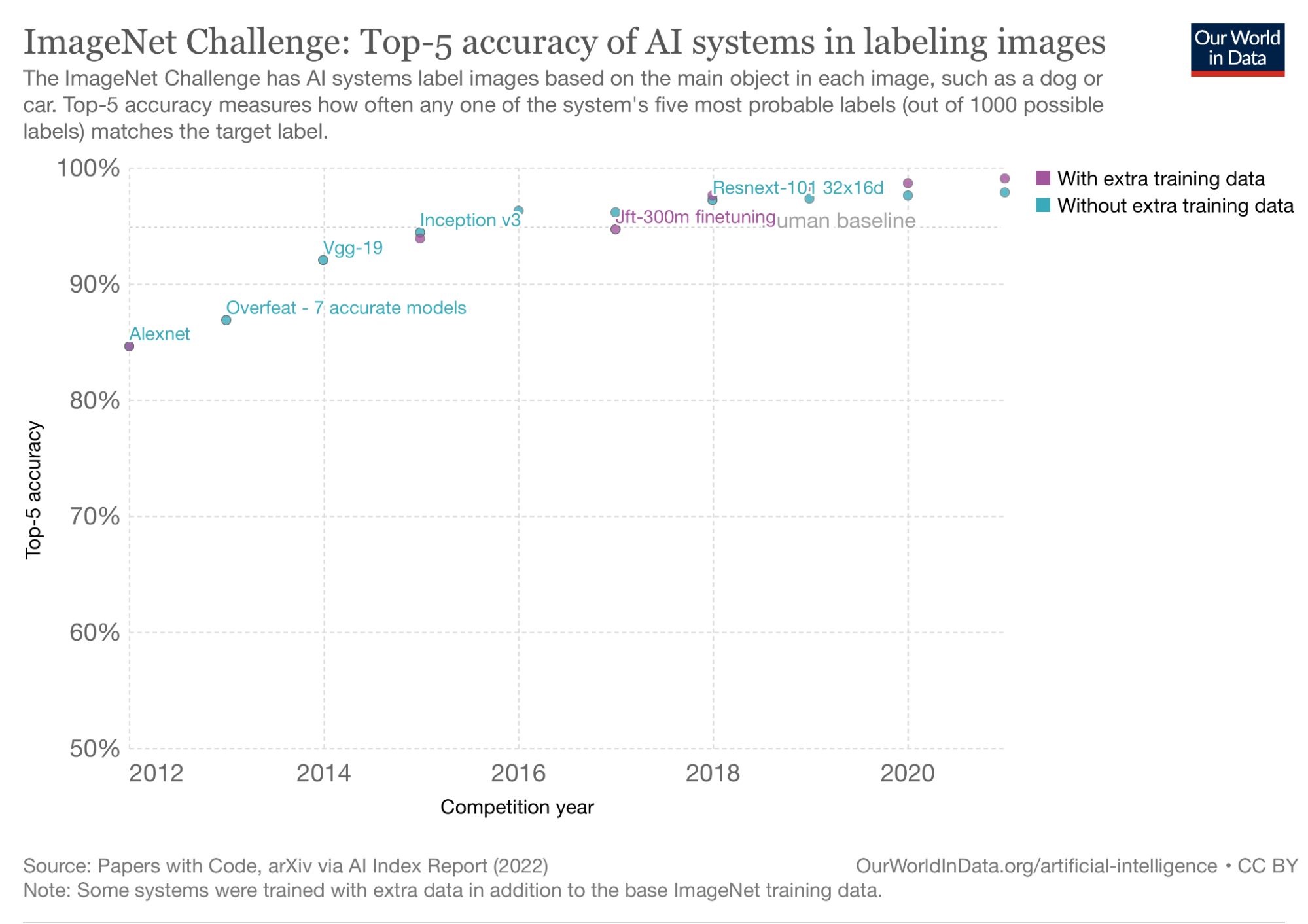
Brownlee und Kollegen untersuchen das Zusammenspiel von Energieaufwand und Modellgenauigkeit systematisch anhand einer festen Architektur, der des
Hierfür testen sie auf unterschiedlich großen Datensätzen unterschiedliche Konfigurationen. Eine Konfiguration besteht dabei aus wählbaren Parametern eines Modells, wie zum Beispiel die
Die Ergebnisse überraschen zunächst nicht. Ist das Modell bei einer Konfiguration besonders genau, dann verbraucht es auch mehr Energie. Den Haupteinfluss nehmen hierbei strukturelle Parameter: Über je mehr Schichten ein neuronales Netz verfügt, desto mehr Kapazität hat es, was sich wiederum in der Genauigkeit widerspiegelt. Doch mehr Schichten heißt auch mehr Rechenoperationen und mehr Energieverbrauch.
Überraschender an den Ergebnissen ist, dass auch nicht-strukturelle Parameter wie der
Die Studie gibt nur einen kleinen Einblick in den Energieverbrauch von KI-Modellen. Obwohl die meisten Modelle in der Praxis auf einer
In den letzten Jahren haben sich einzelne Forschungsgruppen zunehmend mit der gezielten Optimierung des Energieverbrauchs von KI-Modellen auseinandergesetzt. Nicht nur aus ökologischen Gründen, sondern auch im Hinblick auf mobile Anwendungen, für die energieeffiziente KI-Modelle höchst relevant sind. Vor dem Hintergrund der Forschungsergebnisse von Brownlee und Co. erscheint es plausibel, bei der Entwicklung eines Modells immer dessen Energieverbrauch mit im Blick zu haben. Gerade dann, wenn durch verhältnismäßig geringe Einbußen in der Genauigkeit hohe Energieeinsparungen zu erzielen sind. Dafür muss die Forschung weg von der Maxime „nur Genauigkeit zählt“ und hin zu Maßstäben, die mehrere Faktoren berücksichtigen.
