Jedes
Damit das Modell lernen kann, wo der Unterschied liegt, muss diese Information zunächst in Form von Trainingsdaten verpackt werden. Oft bestehen diese Trainingsdaten aus einer Eingabe, zum Beispiel einem Bild, und einem Label, zum Beispiel „anzüglich“ oder „nicht-anzüglich“. Um diese Labels zu bekommen, muss also jemand für jedes Bild in den Trainingsdaten entscheiden, ob es anzüglich ist oder nicht. Wir sprechen hierbei von „supervised learning“, also überwachtem Lernen, da dem Modell durch das Label gesagt wird, was die richtige Antwort ist.
Ist der Datensatz erstellt, kann das Modell auf Grundlage dieser Trainingsdaten eine Entscheidungsregel lernen und diese auf neue Bilder anwenden, die es zuvor noch nicht gesehen hat. Das heißt aber gleichzeitig: Was auch immer der Mensch in die Daten packt, das Modell wird vermutlich lernen, es zu reproduzieren. Im Prinzip ist das ja genau das Ziel. Aber man „kann davon ausgehen, dass gesellschaftliche Stereotype in den Trainingsdaten landen“, betont Carsten Schwemmer, Professor für Soziologie und computergestützte Sozialwissenschaften an der LMU München. In diesem Fall sprechen wir von einem Data Bias, und der ist kritisch.
Ein
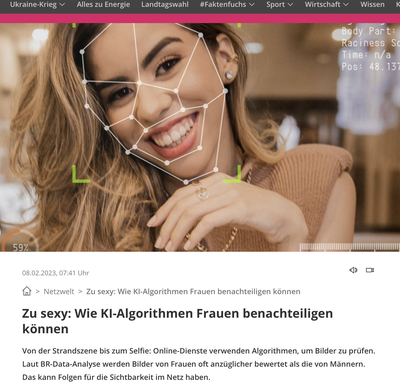
Brunner, Harlan und Reitmeir stellen bei allen vier Diensten zur Erkennung von anzüglichen Bildern, darunter auch in Systemen namhafter Softwareentwickler wie Google, Microsoft und Amazon, ein Data Bias bezüglich des Geschlechts fest: Bilder weiblich erscheinender Personen werden öfter als anzüglich eingestuft als bei männlichem Erscheinungsbild. Im Beitrag werden mehr und weniger offensichtliche Beispiele gezeigt. Bedeutsam ist hier die starke Varianz in den Einstufungen der Anbieter; selbst bei vermeintlich unumstrittenen Fällen schert mindestens einer der Anbieter stark aus. Als Leser kann man hier selbst eine Einschätzung abgeben, bevor man die Ausgaben der Modelle sieht. Die Anbieter geben die Verantwortung an den Nutzer weiter. Kein Filter sei zu 100% genau. Außerdem gäben die Dienste lediglich Wahrscheinlichkeiten dafür an, ob ein Bild anzüglich ist oder nicht. Die Kunden müssen dann eigenverantwortlich entscheiden, wie sie mit der Information und den Bildern umgehen.
Sexistisch, rassistisch oder anders diskriminierend: Die Algorithmen lernen zu reproduzieren und spiegeln so unsere gesellschaftlichen Vorurteile wider. „Im schlimmsten Fall – und das ist der Fall, wenn die Modelle nicht sorgfältig erstellt werden – endet man damit, dass man Stereotype automatisiert und Modelle erstellt, die weit von der Realität entfernt und damit letztendlich schädlich sind, sagt die Kognitionswissenschaftlerin Abeba Birhane
Letzten Endes müssen wir als Gesellschaft entscheiden, wie und wo KI angewandt werden soll, an welchen Stellen mehr Regulierung notwendig ist oder KI-Algorithmen überhaupt nicht verwendet werden sollten. Wie auch immer wir das realisieren, um in Zukunft stark skalierende Diskriminierung zu verhindern, muss uns zunächst bewusst werden, welche Stereotype wir alle unbewusst in uns tragen.