


The bigger, the better?
Ausgelöst von
Der Trend zu immer größeren Modellen ist vor allem aus Ressourcengründen nicht nachhaltig: Große Modelle brauchen viele Ressourcen in Form von Rechenleistung, Geld und Expertise. Gerade Rechenleistung und Geld sind die Gründe, die den Economist zu seinem Urteil veranlassen, denn die Anschaffung der entsprechenden Hardware und die Stromkosten sind teils immens. Aber auch die benötigte Expertise führt dazu, dass sich die Entwicklung von LLMs auf wenige Wettbewerber begrenzt, die es sich leisten können, die entsprechenden Fachleute anzuwerben.
Neben der ökonomischen Nachhaltigkeit gibt es aber noch weitere Nachhaltigkeitsaspekte, die gegen die Entwicklung immer größerer Modelle sprechen. In einem Forschungspapier von 2019 zeigen Strubell und Kolleg:innen, dass das Training eines großen Sprachmodells denselben CO2-Fußabdruck haben kann wie fünf Autos in ihrer gesamten Lebenszeit. Und auch aus demokratischer Perspektive sind die stetig wachsenden Modelle nicht nachhaltig. Schon seit einigen Jahren wird die ML-Forschung von
Alles doch nicht so schlimm?
Dennoch müssen die Emissionen von ML-Modellen in einen größeren Kontext gesetzt werden. Mehrere Studien kommen zu dem Ergebnis, dass der komplette Informations- und Kommunikationstechnik-Sektor (IKT) für 1,9 bis 3,2 Prozent des globalen CO2-Ausstoßes verantwortlich ist.
Was wir über die Emissionen im ML-Lebenszyklus wissen (und was nicht)
Wie Sasha Luccioni und Alex Hernandez-Garcia in ihrem Paper Counting Carbon feststellen, scheint es in der ML-Community kein ausreichendes Bewusstsein für die Dokumentation der eigenen Emissionen zu geben.
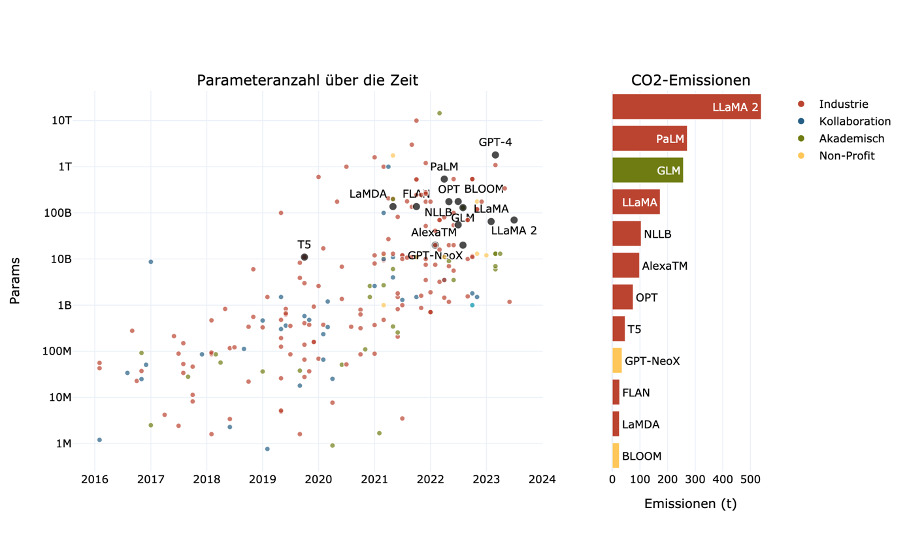
Es lässt sich also klar sagen, dass es ein Dokumentationsdefizit bei den Emissionen für ML-Training gibt. Wenn wir uns die Entwicklung zu immer größeren Modellen ansehen (Abbildung 1),
Wie steht es um die Dokumentation der Emissionen für die Hardware und den Einsatz der Modelle? Eines der wenigen Projekte, das die Emissionen der Hardwareproduktion in seine Kalkulation einbezieht, ist das Big Science-Projekt für das Modell Bloom.
Aktuell lässt sich allerdings erahnen, dass weder die Hardwareproduktion noch das Training die größten Faktoren für die ML-Emissionen sind, sondern die Inferenz, also der Einsatz von Modellen in der Praxis. Für Meta wird berichtet, dass die ML-Emissionen zu 40 Prozent von der Inferenz stammen.
Große Modelle, große Emissionen. Kleine Modelle, kleine Emissionen
ML und KI werden häufig mit Big Tech in Verbindung gebracht. Es gibt aber auch eine Vielzahl an kleineren Projekten, von denen viele eine Gemeinwohlausrichtung haben. In unserer Forschungsgruppe „Public Interest AI“ am Humboldt Institut für Internet und Gesellschaft haben wir vor einiger Zeit eine Studie zu mehreren dieser Projekte verfasst und auf einer interaktiven Karte dokumentiert.
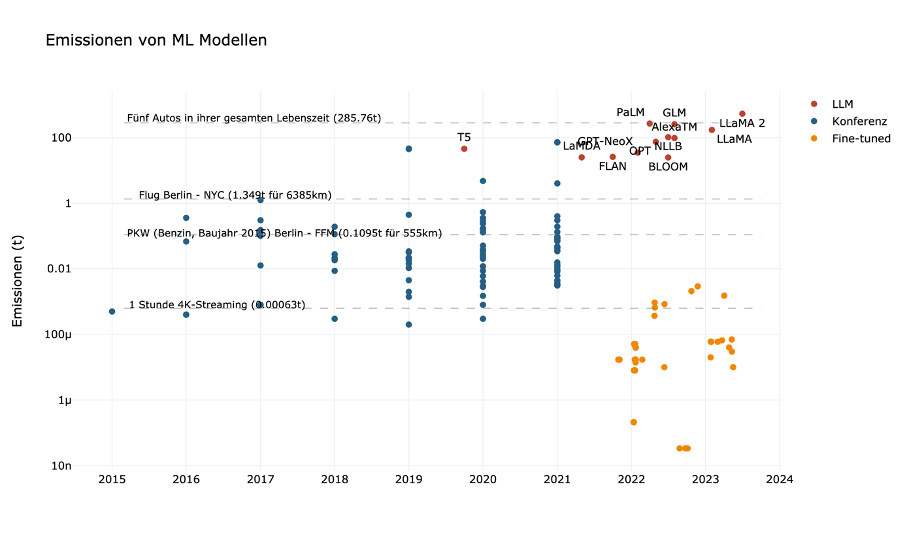
In Abbildung 2 finden sich die CO2-Emissionen von ML-Projekten verschiedener Größenordnungen.
Effizienz statt Wachstum
Ende Februar dieses Jahres verkündete Meta, dass sie das Sprachmodell LLaMA für die Forschung veröffentlichen. Entsprechenden Einrichtungen wurde die Möglichkeit gegeben, sich für den exklusiven Zugang zu bewerben. Nur eine Woche später wurde das Modell allerdings geleaked und war von dann an offen im Netz verfügbar. Man könnte nun meinen, dass dies negative Folgen für Meta gehabt hätte, aber tatsächlich wurde dieser Vorfall selbst von der Konkurrenz als Glücksfall gewertet. In einem geleakten Memo eines Softwareentwicklers von Google heißt es, dass Meta nun kostenfreie Mitarbeit erhalte. Dies begründete er damit, dass künftige Innovationen durch den Leak vermutlich auf der LLaMA-Architektur basieren würden. Und tatsächlich hat sich diese Prognose bewahrheitet. Schaut man auf das Open LLM Leaderboard von Hugging Face, das LLMs der Open-Source-Community listet, bauen die meisten Ansätze auf LLaMA auf (Abbildung 3). Auch Meta scheint diese Entwicklung zu begrüßen. Kürzlich wurde LLaMA 2 veröffentlicht. Diesmal ist es allerdings direkt für alle offen zugänglich und sogar mit einer Lizenz zur kommerziellen Verwendung versehen, was bei bisherigen LLMs selten ist.
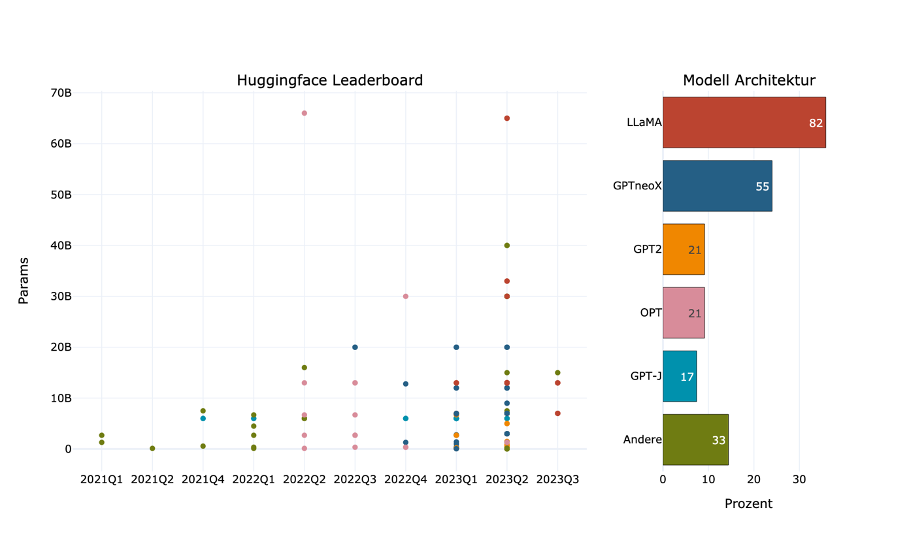
Wie in dem Google-Memo beschrieben, hat sich die Open-Source-Community in den letzten Monaten zu einem ernsthaften Mitbewerber bezüglich LLMs entwickelt. Eine treibende Kraft ist Hugging Face, eine Plattform, die über 150.000 vortrainierte ML-Modelle hostet und die maßgebliche Schnittstelle ist, um freien Zugang zu LLMs zu bekommen.
Ein Beispiel für die Innovationskraft der Open-Source-Szene ist die sogenannte Quantisierung. Bei Quantisierung geht es darum, die Parameter eines Modells in einem kleineren Datenformat zu speichern. Ein ML-Modell ist eigentlich nichts anderes als eine Ansammlung von Parametern, also Zahlen. Vor einigen Jahren ging es noch um eine Parameteranzahl von einigen Millionen, mittlerweile sind mehrere Millarden nicht mehr ungewöhnlich (Abbildung 3). Jede dieser Zahlen wird standardgemäß mit je 32 Bit dargestellt. Quantisierung bedeutet nun nichts anderes, als dass auf weniger Bit reduziert wird.
Beachtlich ist, dass diese Errungenschaften nicht auf große Tech-Firmen zurückgehen. Eine der erfolgreichsten
Transparenz, Effizienz und Differenzierung
Viele Akteure in der aktuellen KI-Entwicklung sind intransparent in Bezug auf ihren CO2-Fußabdruck und setzen vor allem auf Wachstum und immer größere Modelle. Auf der anderen Seite gibt es viele Projekte, bei denen es anders läuft und entsprechend sind Pauschalisierungen nur schwer möglich. Welche Lehren und Zukunftsperspektiven können wir daraus ableiten? Ich denke, dass die zukünftige KI-Entwicklung von Transparenz, Effizienz und Differenzierung geleitet werden sollte.
Zunächst braucht es eine weitaus rigorosere Dokumentation von Emissionen, und zwar nicht nur für das Training von ML-Modellen, sondern für alle Abschnitte des Lebenszyklus. Ich habe Hardwareherstellung und Inferenz genannt. Aber auch die Datengewinnung, -übertragung und -bereinigung sind wesentliche Faktoren. Auch andere Nachhaltigkeitsfaktoren wie z.B. der Wasserverbrauch für Datenzentren müssen berücksichtigt werden. Eine Möglichkeit ist es, dass auf Konferenzen und Publikationen im Allgemeinen nicht nur Performance, sondern auch Rechenaufwand in den Metriken berücksichtigt wird.
Damit wären wir auch direkt bei Effizienz, denn mit umfassenderen Metriken würden auch schlankere Modelle mit nur leicht verminderter Performance in den Fokus rücken. Eine Möglichkeit besteht in der Quantisierung, aber auch mehr Fokus auf
Zuletzt sollten wir differenzierter auf unterschiedliche ML-Projekte blicken. Es gibt eine Vielzahl an kleinen bis mittleren ML-Projekten, die eine wissenschaftliche oder gemeinwohlorientierte Ausrichtung und nur unwesentliche Emissionen haben. Ein zu strikter Blick auf deren CO2-Ausstoß könnte negative Folgen haben, denn häufig fehlen die Kapazitäten, um zusätzlich auf die höchste Effizienz zu achten.
Wenn wir uns die vorigen Abbildungen anschauen, wird schnell klar: In Bezug auf ökologische Nachhaltigkeit haben wir in erster Linie kein KI-, sondern ein Big-Tech-Problem. Es sind die großen Modelle, die hohe Emissionen freisetzen und deren Trainingsdaten und Programmcode hinter verschlossenen Türen bleiben, während kleinere Projekte ihren Code meist veröffentlichen und häufig nicht mehr Emissionen freisetzen, als wenn man Arielle, die Meerjungfrau streamen würde.